攚宨
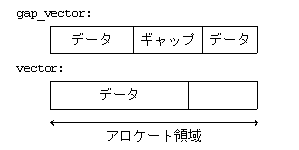
- 僔乕働儞僗乮侾師尦揑偵暲傫偩乯僨乕僞傪娗棟偡傞僨乕僞峔憿偲偟偰偼丄乽攝楍乿乽憃曽岦儕僗僩乿偺俀偮偑堦斒揑偱偁傞丅
- 偙傟傜偼憡曗揑側摿挜傪帩偮丅
- 偡側傢偪丄攝楍偼丄儔儞僟儉傾僋僙僗偑 O(1) 偱偁傞偑丄憓擖丒嶍彍偲偄偭偨曇廤張棟偑 O(N) 偱偁傞丅
- 憃曽岦儕僗僩偼丄曇廤張棟偼 O(1) 偱偁傞偑丄儔儞僟儉傾僋僙僗偼 O(N) 偱偁傞丅
- 堦斒揑偵嫋梕弌棃傞偺偼 O(log N) 傑偱偱偁傝丄攝楍丒憃曽岦儕僗僩偲傕偵丄僔乕働儞僗僨乕僞梡僨乕僞峔憿偲偟偰偼栤戣偑偁傞丅
- 僥僉僗僩僄僨傿僞偼暥帤偺僔乕働儞僗僨乕僞傪庢傝埖偆傕偺偱偁傝丄儔儞僟儉傾僋僙僗偲曇廤張棟偑崅懍偱偁傞昁梫偑偁傞丅
- 僥僉僗僩僄僨傿僞偺僨乕僞峔憿偲偟偰丄乽攝楍乿傑偨偼乽憃曽岦儕僗僩乿傪偦偺傑傑梡偄傞偺偼丄忋婰偺揰偱岲傑偟偔側偄丅
- 傂偲偮偺夝寛曽朄偲偟偰丄夵峴偱嬫愗傜傟傞侾峴傪摦揑攝楍偱娗棟偟丄峴傪憃曽岦儕僗僩偱娗棟偡傞偲偄偆傕偺偑偁傞丅
劇劅劅劅劉 劆 劆 劆 劇劅劏劅劉 劇劅劅劅劅劅劅劅劅劉 劆 劆 劆劅劅仺劆峴僥僉僗僩僨乕僞劆 劆 劋劅劍劅劊 劋劅劅劅劅劅劅劅劅劊 劆 劆 劆 劇劅劏劅劉 劇劅劅劅劅劅劅劅劅劉 劆 劆 劆劅劅仺劆峴僥僉僗僩僨乕僞劆 劆 劋劅劍劅劊 劋劅劅劅劅劅劅劅劅劊 劆 劆 劆 劇劅劏劅劉 劇劅劅劅劅劅劅劅劅劉 劆 劆 劆劅劅仺劆峴僥僉僗僩僨乕僞劆 劆 劋劅劍劅劊 劋劅劅劅劅劅劅劅劅劊 丗 丗 丗 丗 劆 劇劅劏劅劉 劇劅劅劅劅劅劅劅劅劉 劆 劆 劆劅劅仺劆峴僥僉僗僩僨乕僞劆 劆 劋劅劍劅劊 劋劅劅劅劅劅劅劅劅劊 劆 劆 劋劅劅劅劊 - 偙偺曽朄偼丄奺峴偑嬌抂偵挿偔側偗傟偽丄曇廤張棟偼傎傏 O(1) 偲側傞丅
- 乽Software Tools乿 乮栿杮乯 偱徯夘偝傟丄傑偨丄弶婜偺 vi 偺僨乕僞峔憿偱偁傝丄偙偺曽朄傪嵦梡偟偨僥僉僗僩僄僨傿僞偼偐側傝懡偄傜偟偄丅
- ViVi version 1.x 傕偙偺僨乕僞峔憿傪乮夵椙偟偨傕偺傪乯嵦梡偟偰偄傞丅
- 寚揰偲偟偰偼丄峴挿偑嬌抂偵戝偒偄峴偑偁傞偲丄曇廤張棟偼 O(N) 偵側傝丄僷僼僅乕儅儞僗偑嬌抂偵棊偪傞丅
- 傑偨丄峴偺儔儞僟儉傾僋僙僗偼弌棃側偄乮ViVi 1.x 偱偼峴斣崋僉儍僢僔儏朄偵傛傝懳墳偟偰偄傞乯丅
- 儔僀儞僄僨傿僞偱偁傟偽丄峴偺儔儞僟儉傾僋僙僗偺崅懍惈偼昁梫惈偼柍偄偺偩偑丄GUI 僄僨傿僞偱悅捈僗僋儘乕儖傪峴偆偲丄 儔儞僟儉傾僋僙僗偵嬤偄忬懺偲側傝丄峴悢偑偐側傝懡偄応崌偼墳摎惈偑埆偔側傞偲偄偆栤戣偑偁傞丅
- 偝傜偵丄峴僥僉僗僩偺偨傔偵 std::string 側偳偺婛懚偺僋儔僗傪梡偄傞偲丄峴悢偑嬌抂偵懡偄応崌丄
彫椞堟儊儌儕偑戝検偵嶌傜傟丄僶僢僼傽僆僽僕僃僋僩傪夝曻偡傞偺偵偐側傝偺帪娫傪梫偡傞乮悢10昩傪梫偡傞偙偲傕偁傞乯丅
- 傕偆傂偲偮偺夝寛曽朄偲偟偰乽僊儍僢僾 僶僢僼傽乿偲偄偆傕偺偑偁傞丅
- 僊儍僢僾僶僢僼傽偲偼丄摦揑側攝楍偱丄曇廤売強傪嫬偵僥僉僗僩僨乕僞傪僶僢僼傽偺愭摢偲枛旜偵媗傔偨傕偺偱偁傞丅
- 曇廤売強偑嬊強揑側応崌丄曇廤張棟偼 O(1) 偲側傞丅偦偟偰丄僥僉僗僩僄僨傿僞偺曇廤売強偼廩暘偵嬊強壔偝傟偰偄傞丅
- 偪側傒偵丄弶婜偺 Emacs 偼丄偙偺僊儍僢僾僶僢僼傽傪嵦梡偟偰偄傞丅
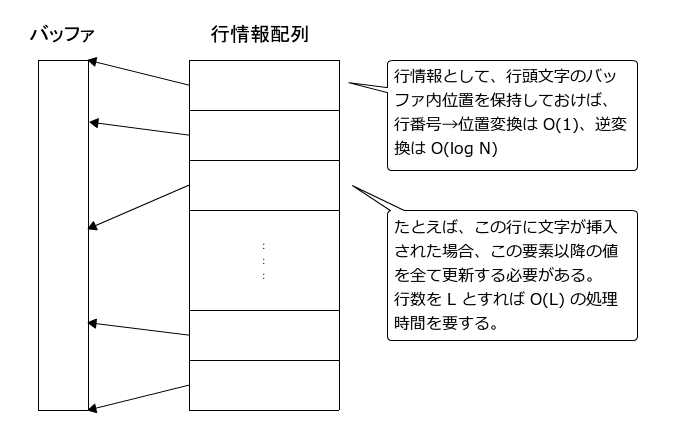
- 僊儍僢僾僶僢僼傽偼僷僼僅乕儅儞僗偑嬃偔傎偳椙偄偺偩偑丄峴偵娭偡傞忣曬傪帩偭偰偄側偄偺偱丄暿搑峴忣曬偺娗棟偑昁梫偲側傞丅
壗屘側傜丄捠忢偺僥僉僗僩僄僨傿僞偼僥僉僗僩傪峴扨埵偱昞帵偡傞偐傜偩丅 - 僊儍僢僾僶僢僼傽偺峴娗棟傪偡傞嵟傕扨弮側曽朄偼丄奺峴偺愭摢埵抲傪摦揑攝楍偱娗棟偡傞傕偺偱偁傞丅
- 偙偺曽朄偱偼丄峴斣崋偐傜僶僢僼傽撪埵抲偺曄姺偼 O(1)丄僶僢僼傽撪埵抲偐傜峴斣崋傊偺曄姺偼 O(log L) 偱嵪傓乮L 偼峴悢乯丅
- 峴悢偑憹尭偟偨応崌偺張棟偼丄峴悢傪 L 偲偡傟偽丄O(L) 側偺偩偑丄攝楍偱偼側偔僊儍僢僾僶僢僼傽偲摨條偺曽幃偵偡傟偽丄O(1) 偲側傞丅
- 栤戣偼丄曇廤偵傛傝僥僉僗僩偑憹尭偟偨応崌偱丄曇廤峴埲崀偺僶僢僼傽撪埵抲傪廋惓偡傞昁梫偑偁傝丄偦偺張棟偼 O(L) 偲側偭偰偟傑偆丅
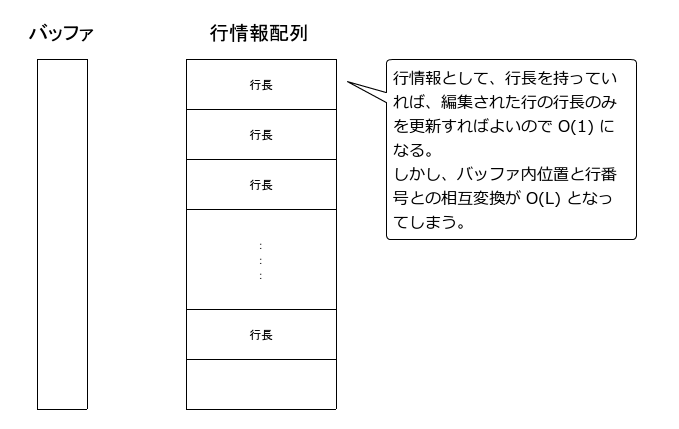
- 曇廤帪偺峴忣曬峏怴張棟傪崅懍壔偡傞偨傔偺曽朄偲偟偰丄奺峴偺愭摢埵抲傪攝楍偱帩偮偺偱偼側偔丄奺峴偺挿偝傪攝楍偱帩偮曽朄偑偁傞丅
- 偙偺曽朄偱偁傟偽丄曇廤帪偺峴忣曬峏怴張棟偼 O(1) 偲側傞丅
- 偟偐偟側偑傜丄峴斣崋偐傜僶僢僼傽撪埵抲偺曄姺丄偍傛傃偦偺媡偺曄姺偼 O(L) 偲側傝丄嫋梕弌棃傞傕偺偱偼側偄丅
- 僉儍僢僔儏傪棙梡偡傞偙偲偱丄曄姺埵抲偑嬊強壔偝傟偰偄傟偽丄張棟帪娫傪 O(1) 偵偡傞偙偲偑偱偒傞 乮ViVi 5.0 偱嵦梡乯丅
- 偟偐偟丄峴悢偑嬌抂偵懡偄応崌偵丄悅捈僗僋儘乕儖傪峴偆偲丄庒姳斀墳偑抶偔側傞婥偑偡傞丅
- 僊儍僢僾僶僢僼傽椶傪巊梡偣偢丄峴僥僉僗僩傊偺億僀儞僞丒峴挿傪峴忣曬偲偟偰曐帩偡傞曽朄傕偁傞丅
- 偙傟偼丄曇廤張棟偑峴傢傟側偗傟偽栤戣偑側偄偺偩偑丄曇廤張棟偑峴傢傟傞偲儊儌儕偺抐曅壔傪堷偒婲偙偡偺偱丄 偄傠偄傠傗偭偐偄偱偁傞丅
採埬庤朄
- 慜愡偱弎傋偨栤戣傪夝寛偡傞偨傔偵丄峴忣曬攝楍偵僶僢僼傽撪埵抲傪曐帩偟丄
曇廤偑峴傢傟偨応崌偼丄嵟屻偺曇廤峴埲崀偺僶僢僼傽撪埵抲傪峏怴偣偢丄嵎暘抣傪曐帩偡傞丄偲偄偆庤朄傪採埬偡傞丅
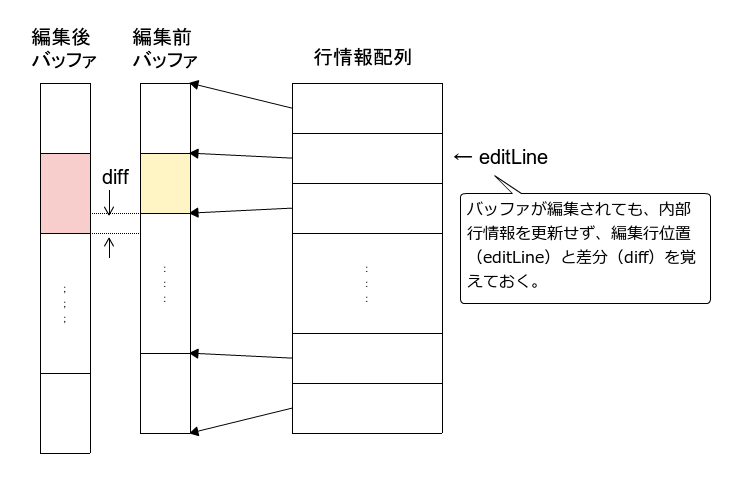
仸 偙偺庤朄偑僆儕僕僫儖偐偳偆偐偼挷嵏偟偰偄側偄丅扨弮側曽朄側偺偱丄偨傇傫扤偐偑婛偵峫偊偰幚憰偟偰傞偲悇應偝傟傞丅
- 偨偲偊偽丄"12\n34\n56\n78\n" 偲偄偆僥僉僗僩偑偁偭偨応崌丄峴忣曬偼 [0, 3, 6, 9, 12] [0, 0]偲昞尰偝傟傞丅
- 嵟弶偺 [0. 3, 6, 9, 12] 偑幚嵺偺攝楍撪偺抣偱偁傞丅
- 峴悢偼4峴偟偐側偄偺偵抣偑俆偮偁傞偺偼丄峴挿偺寁嶼傪扨弮壔偡傞偨傔偱偁傞丅
峴忣曬攝楍傪 lines[] 偲偡傟偽丄ix (0..*) 斣栚偺峴偺挿偝偼 lines[ix + 1] - lines[ix] 偱娙扨偵寁嶼偱偒傞丅
媡偵尵偊偽丄嵟弶偺抣偼忢偵乽0乿側偺偱丄偙傟傕忕挿偲尵偊偽忕挿偩偑丄峴挿寁嶼傪扨弮壔偡傞偨傔偵巆偟偰偄傞丅
堦庬偺斣恖偱偁傞丅 - [0, 0] 偼曇廤峴丒嵎暘抣偱偁傞丅嵎暘抣偑乽0乿偺応崌丄曇廤峴偼堄枴傪帩偨側偄偺偱壗偱偁偭偰傕傛偄丅
- 2峴栚乮"34\n"偺峴乯偵夵峴埲奜偺暥帤傪3暥帤憓擖偡傞偲丄峴忣曬偼 [0, 3, 6, 9, 12] [1, 3] 偲側傞丅
- 曄壔偟偨偺偼丄曇廤峴丒嵎暘抣偺傒偱偁傞丅
- 撪晹僨乕僞偼 [0, 3, 6, 9, 12] 偺傑傑偱偁傞偑丄俀峴栚偑曇廤峴側偺偱丄俁峴栚埲忋偺峴偺埵抲傪寁嶼偡傞応崌偼丄 嵎暘偺乽3乿傪壛偊傞丅廬偭偰丄奜晹偐傜尒偨応崌偼 [0, 3, 9, 12, 15] 偲側傞丅
- 偝傜偵俁峴栚偵夵峴埲奜偺暥帤傪侾暥帤憓擖偡傞偲丄[0, 3, 9, 9, 12] [2, 4] 偲側傞丅
- 崱夞偼攝楍偺俁峴栚偺抣偑乽6乿偐傜乽9乿偵曄壔偟偰偄傞丅
- 偙偺傛偆偵丄捈慜偺曇廤峴偲崱夞偺曇廤峴偑堎側傞応崌偼丄峴斣崋偺嵎暘偩偗偺攝楍梫慺偺峏怴偑昁梫偲側傞丅
- 偟偐偟丄僥僉僗僩僄僨傿僞偺応崌丄曇廤売強偼嬊強壔偝傟偰偄傞偲偄偆尨棟偑偁傞偺偱丄偙偺張棟偼傎傏 O(1) 偲側傞丅
- 杮庤朄偵傛傝丄峴斣崋偐傜僶僢僼傽撪埵抲偺曄姺張棟傪 O(1)丄媡偺曄姺傪 O(log L) 偵曐偭偨傑傑丄 曇廤帪偺張棟傪 O(1) 偵偡傞偙偲偑弌棃傞丅
幚憰
- 撪晹揑側峴忣曬傪丄摦揑攝楍 lines[] : size_t 偱娗棟偡傞丅
- lines[] 偺梫慺悢偼幚嵺偺峴悢 + 1 偲偟丄奺峴偺愭摢暥帤偺僶僢僼傽撪埵抲乮size_t乯傪曐帩偡傞丅
- lines[] 偺嵟屻偺梫慺偼丄僶僢僼傽僒僀僘傪抣偲偟偰曐帩偡傞丅
- 嵟廔曇廤峴偼 editLine : size_t 偱昞偡乮0 僆儕僕儞乯丅弶婜抣偼擟堄丅
- 嵟廔曇廤峴埲崀偺嵎暘偼 diff : diffptr_t 偱昞偡丅弶婜抣偼 0 偱偁傞丅
- ix (0..*) 斣栚偺峴偺埵抲偼丄埲壓偺寁嶼幃偱梌偊傜傟傞丅
丂丂丂丂lines[ix] + (ix > editLine ? diff : 0)
- ix (0 僆儕僕儞) 峴偑 d 偩偗曄壔偟偨応崌偺丄峴忣曬峏怴張棟傾儖僑儕僘儉偼埲壓偺傛偆偵婰弎偱偒傞丅
1: void update(size_t ix, diffptr_t d) 2: { 3: if( !diff ) { // 嵎暘偑 0 偺応崌 4: editLine = ix; 5: } else if( ix < editLine ) { // 曇廤峴埲慜傪曇廤偟偨応崌 6: while( editLine > ix ) { 7: lines[editLine--] -= diff; 8: } 9: } else if( ix > editLine ) { // 曇廤峴埲崀傪曇廤偟偨応崌 10: do { 11: lines[++editLine] += diff; 12: } while( ix > editLine ); 13: } 14: diff += d; 15: }
僷僼僅乕儅儞僗寁應
- 僥僉僗僩僄僨傿僞梡僶僢僼傽偺憤崌揑側僷僼僅乕儅儞僗昡壙偲偟偰偼丄慡抲姺張棟偵梫偡傞帪娫傪寁應偡傞偺偑嵟傕傛偄丅
- 壗屘側傜丄慡抲姺張棟偼丄僥僉僗僩僄僨傿僞偵偲偭偰嵟傕昿斏偵僐乕儖偝傟傞丄僶僢僼傽撪僥僉僗僩偺僔乕働儞僔儍儖傾僋僙僗丄 嶍彍丄抲姺張棟傪娷傫偱偄傞偐傜偱偁傞丅
- 斾妑偺偨傔偵丄採埬庤朄偵傛傞幚憰丄gap_vector<uchar>, gap_vector<std::string> 偺俁偮偵偮偄偰寁應偡傞丅
- 斾妑懳徾偼 undo/redo 婡擻傪帩偨側偄偺偱採埬庤朄偵傛傞傕偺傕 undo/redo 婡擻傪幚憰偟側偄傕偺偱斾妑偡傞丅
- ("abc1234567" * 10 + "\n") * 10枩峴乮崌寁丗1.01*10^7僶僀僩乯偵懳偟偰嶍彍側偳偺張棟傪峴偄丄張棟偵梫偟偨帪娫傪寁應偟偨丅
- 嶍彍丗3暥帤嶍彍偟丄7暥帤恑傔傞丅夵峴偼僗僉僢僾丅100枩売強丄300枩僶僀僩傪嶍彍
- 憓擖丗2暥帤嶍彍偟丄10暥帤恑傔傞丅夵峴偼僗僉僢僾丅100枩売強丄200枩僶僀僩傪嶍彍
- 抲姺丗3暥帤傪5暥帤偵抲姺偟丄7暥帤恑傔傞丅夵峴偼僗僉僢僾丅100枩売強丄300枩僶僀僩傪嶍彍丒500枩僶僀僩傪憓擖
- 専嶕丒抲姺丗"123" 傪専嶕偟丄"xyzzz" 偵抲姺丅100枩売強丄300枩僶僀僩傪嶍彍丒500枩僶僀僩傪憓擖
- 仸 寁應娐嫬丗Core i5 670 @3.47GHz 3.46GHz丄4GB RAM, VC9, Win7 x64
- 寁應寢壥偼壓昞偺偲偍傝乮扨埵丗昩乯丗
採埬庤朄 gap_vector<char> gap_vector<string> 嶍彍 0.106 0.023 0.108 憓擖 0.109 0.092 0.335 抲姺 0.160 0.101 0.322 専嶕仌抲姺 0.250 0.185 0.346 - 採埬庤朄偼 gap_vector<char> 傪撪曪偟偰偄傞偺偱丄乮採埬庤朄乯-乮gap_vector<char>乯偑峴娗棟張棟偵旓傗偟偰偄傞帪娫偲側傞丅
- gap_vector<string> 偼嶍彍偲偦傟埲奜偱栺3攞傕偺張棟帪娫嵎偑偁傞丅偙傟偼僶僢僼傽椞堟傪嵞傾儘働乕僩仌僐僺乕傪峴偭偰偄傞偨傔偱偁傞丅
峫嶡丒寢榑
- 杮庤朄偼旕忢偵僔儞僾儖偱偁傞丅
- 婛偵嵎暘忣曬偑偁傞応崌丄捈慜偺曇廤峴偲偼堎側傞峴傪曇廤偟偨応崌偼丄偦偺娫偺撪晹峴忣曬攝楍梫慺傪峏怴偡傞昁梫偑偁傞偑丄
僥僉僗僩僄僨傿僞偱偼曇廤売強偼嬊強壔偝傟偰偄傞偲偄偆摿惈偑偁傞偨傔傫丄傎偲傫偳偺応崌峏怴偑昁梫側梫慺悢偼彮側偔丄
張棟帪娫偼傎傏 O(1) 偲側傞丅
- 僶僢僼傽偺愭摢晅嬤偑曇廤偝傟丄偮偄偱僶僢僼傽偺枛旜晅嬤偑曇廤偝傟偨応崌偼丄峴忣曬偺傎偲傫偳偺梫慺偑峏怴偝傟傞丅
偙傟偼堦尒栤戣偺傛偆偩偑丄偦偺傛偆側応崌偼丄僊儍僢僾儀僋僞偱僨乕僞偺戝検堏摦偑峴傢傟偰偍傝丄 偦偪傜偺張棟帪娫偺曽偑巟攝揑偵側傞丅 - 尦乆偺慜採偱偁傞乽曇廤憖嶌偼嬊強揑偱偁傞乿偑曵傟偨忬嫷偱偁傞偺偱丄張棟帪娫傪梫偡傞偺偼摉慠偱偁傝丄栤戣帇偟側偄丅
- 枛旜晅嬤乮枛旜偐傜悢昐峴掱搙丠乯偱偺曇廤偺応崌丄偦偺峴埲崀偺峴忣曬傪捈愙峏怴偟偰傕丄 張棟帪娫偼柍帇偱偒傞掱搙偱偁傞偐傜丄偦偺応崌偼曇廤峴丒嵎暘抣傪峏怴偟側偄丄偲偄偆夵椙傕峫偊傜傟傞丅