媄弍暥復亜僥僉僗僩僄僨傿僞幚憰媄弍偦偺俀
僥僉僗僩僄僨傿僞梡僶僢僼傽偺奣梫偵偝傜偭偲怗傟丄奒憌揑僨乕僞峔憿偍傛傃僺乕僗僥乕僽儖乮piece table乯偵偮偄偰弎傋傞丅
偦傟傜傪昅幰偑幚憰偟偨僋儔僗偵偮偄偰僷僼僅乕儅儞僗寁應傪峴偭偨寢壥傪曬崘偡傞丅
栚師丗
僶僢僼傽偲偼1師尦揑偵暲傫偩暥帤傪娗棟偡傞僋儔僗偱偁傞丅
僔乕働儞僔儍儖傾僋僙僗丄曇廤乮嶍彍丒憓擖乯婡擻偑昁恵 乮暥帤僀儞僨僢僋僗丄峴斣崋偵傛傞儔儞僟儉傾僋僙僗傕偱偒偨曽偑傛偄乯
昁梫廩暘側婡擻丒崅怣棅惈丒崅懍惈丒儊儌儕岠棪偺椙偝丒奼挘惈 偑媮傔傜傟傞
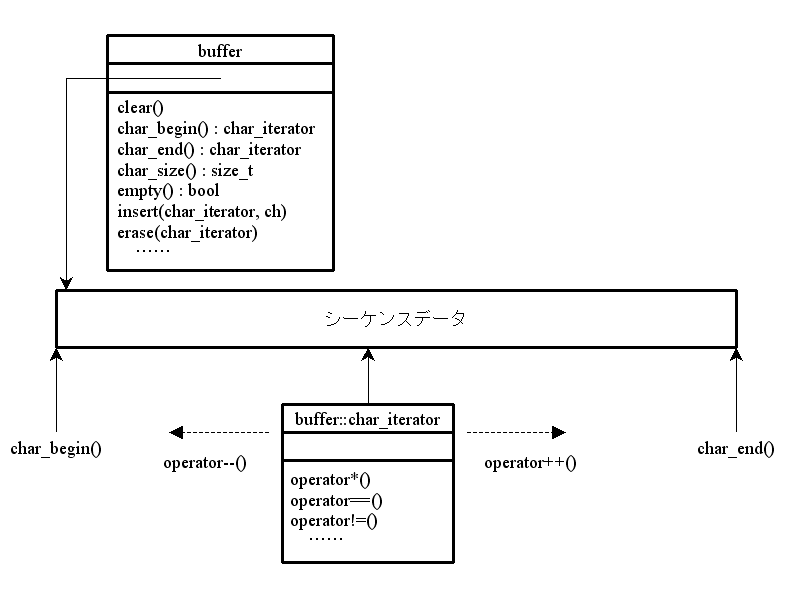
壓恾偺條側STL屳姺偺 C++僀儞僞僼僃乕僗傪掕媊偡傞偙偲偑偱偒傞
僔乕働儞僗僨乕僞偺僨乕僞峔憿偼僋儔僗偵傛傝條乆偱丄偦傟偵傛傝僶僢僼傽僋儔僗偺摿挜丒惈擻偑寛傑傞丅
慡抲姺偺椺丗
void replace_all(CEditBuffer &eb, const string &pat, const string &rep)
{
CEditBuffer::char_iterator itr = eb.char_begin();
CEditBuffer::char_iterator eitr = eb.char_end();
while( (itr = find_string(itr, eitr, pat)) != eitr ) { // 僷僞乕儞傪専嶕
itr = eb.erase(itr, itr + pat.size()); // 僷僞乕儞傪嶍彍
itr = eb.insert(itr, rep); // 抲姺暥帤楍傪憓擖
++itr;
eitr = eb.char_end();
}
}
gap_vector<char> 偼嬃偔傎偳崅惈擻乮懍搙丄儊儌儕岠棪乯
偨偩偟丄嫄戝側暥彂偵懳偟偰偼栤戣偑柍偔偼側偄
僼傽僀儖僒僀僘偑戝偒偔丄撉傒崬傒偵帪娫偑偐偐偭偨傝丄儊儌儕偵慡晹傪撉傒崬傓偙偲偑偱偒側偄応崌偑偁傞丅
慜幰偺懳嶔偲偟偰 ViVi 2.x 偱偼抶墑儕乕僪婡擻傪幚憰偟偰偄傞偑丄僼傽僀儖枛旜偐傜撉傒崬傓偙偲偑弌棃側偄側偳偺栤戣偑偁傞丅
壖憐儊儌儕偺傛偆偵庡婰壇偵撉傒崬傔側偄僨乕僞偼奜晹婰壇憰抲忋偵抲偒丄
僋儔僗奜偐傜偼僔乕儉儗僗偵棙梡偱偒傞偺偑朷傑偟偄丅
壖憐僶僢僼傽丠
撪晹僐乕僪傪Unicode側偳偵屌掕偟偨応崌丄僼傽僀儖撉崬帪偺曄姺偵帪娫揑嬻娫揑僐僗僩偑偐傞
偐偲尵偭偰嶲徠偺偨傃偵曄姺傪峴偆偺偼張棟帪娫揑偵栤戣偐傕偟傟側偄
偙偺傛偆側応崌丄曄姺寢壥傪僉儍僢僔儏偡傞偺偑掕愓偩偑丄gap_vector 偲偺憡惈偼傛偔側偄丅
僨乕僞峔憿偑峴扨埵偱側偄応崌丄峴悢僇僂儞僩張棟偑暿搑昁梫偵側傞丅
曇廤僼儔僌側偳偺峴扨埵忣曬偺娗棟傕昁梫
gap_vector<char> 傪巊梡偡傞応崌偼丄峴僼儔僌忣曬傪暿搑曐帩偡傞偐丄僔乕働儞僗僨乕僞偵杽傔崬傓昁梫偑偁傞丅
屻幰偺応崌丄暥帤僆僼僙僢僩傪巜昗偲偡傞儔儞僟儉傾僋僙僗偑晄壜擻偵側傞偟丄僔乕働儞僔儍儖傾僋僙僗懍搙傕掅壓偡傞丅
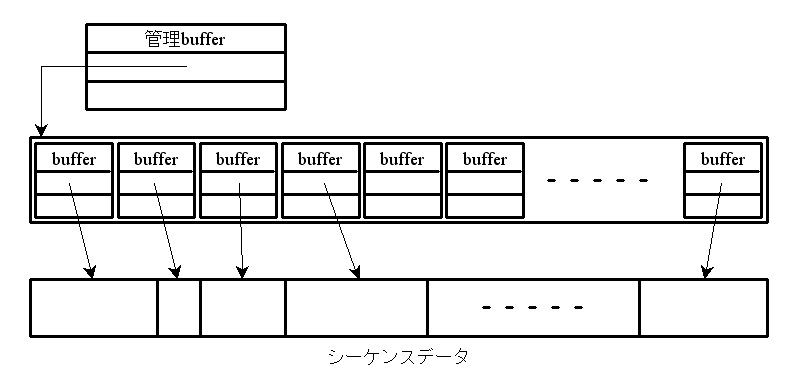
僔乕働儞僗側僨乕僞傪庢傝埖偆僨乕僞峔憿偼懡庬椶偁傝丄堦挿堦抁偑偁傞
偦傟傜傪壓恾偺條偵奒憌揑乮嵞婣揑丠乯偵攝抲偡傞偙偲偱丄堎側偭偨摿挜傪帩偮僨乕僞峔憿傪嶌傞偙偲偑偱偒傞
偨偲偊偽丄array乮屌掕挿攝楍乯偼僔乕働儞僗僨乕僞傪庢傝埖偆偺偵嵟傕帺慠側僨乕僞峔憿偩偑丄
僒僀僘屌掕偱偁傞偨傔偵僶僢僼傽偵梡偄傞偵偼擄偑偁傞丅
偟偐偟丄vector<array<char>> 偺傛偆偵丄壜曄屄偺 array 傪 vector 偱娗棟偟偰傗傟偽丄
屌掕挿偲偄偆僨儊儕僢僩偑抳柦揑側傕偺偱偼側偔側傞丅
偨偩偟丄娗棟僐僗僩偑怴偨偵敪惗偡傞偺偱丄娗棟丒旐娗棟僨乕僞峔憿傪怲廳偵慖傇昁梫偑偁傞丅
| 僨乕僞峔憿 | 奣梫 | 儔儞僟儉傾僋僙僗 | 憓擖嶍彍 |
|---|---|---|---|
| array | 屌掕挿攝楍 | O(1) | O(N)丄僒僀僘傪挻偊傞僨乕僞傪奿擺偱偒側偄 |
| vector | 壜曄挿攝楍 | O(1) | O(N) |
| gap_vector | 拞墰偵 gap 傪帩偮壜曄挿攝楍 | O(1) | 嬊強揑偱偁傟偽 O(1) |
| list | 憃曽岦儕僗僩 | O(N) | O(1) |
| list with cache | 僉儍僢僔儏晅偒憃曽岦儕僗僩 | 嬊強揑偱偁傟偽 O(1) | O(1) |
| BST | 擇暘扵嶕栘乮僶儔儞僗擇暘栘乯 | O(logN) | O(logN) |
| 僗僷儞 | 僨乕僞椞堟傪強桳偟側偄攝楍揑側傕偺 | O(1) | 捈愙揑側憓擖嶍彍偼偱偒側偄 |
vector椶傪vector椶偱娗棟偡傞慻傒崌傢偣偵偮偄偰丄峫嶡偲僷僼僅乕儅儞僗應掕傪峴偆丅
應掕崁栚偼埲壓偺崁栚偲偡傞丅
嵟傕婎杮揑側慻傒崌傢偣丅
STL 偵偼 array 偑柍偄偺偱丄reserve 偱偁傜偐偠傔椞堟傪妋曐偟僒僀僘傪屌掕偵偟偨 vector<char> 傪戙傢傝偵梡偄傞丅
array 偺僒僀僘偼 32KB 偲偟偰傒傞丅array 僒僀僘傪曄偊偨応崌偺寁應偼梋桾偑偁傟偽峴偆丅
暥帤僨乕僞偑 array 僒僀僘埲忋偵側偭偨応崌丄壜擻側傜慜屻偺 array 偵憲傞丅偦偆偱側偄応崌偼怴偨偵 array 傪嶌惉偡傞丅
曇廤僐僗僩偍傛傃僽儘僢僋暘妱帪僐僗僩偼丄僽儘僢僋僒僀僘傪 B 偲偡傟偽 O(B) 偱偁傞丅
僽儘僢僋僒僀僘偼彫偝偄傎偳傛偄偑丄偁傑傝彫偝偄偲娗棟僐僗僩偑憹戝偡傞丅
娗棟僋儔僗傪 vector 偐傜 gap_vector 偵曄偊偨傕偺丅
僽儘僢僋偺憓擖嶍彍偑嬊強揑偐偮昿斏偱偁傟偽丄僷僼僅乕儅儞僗偺岦忋偑婜懸偱偒傞丅
僽儘僢僋偺僨乕僞峔憿傪 array 仺 屌掕僒僀僘 gap_vector 偵曄偊偨傕偺丅
僽儘僢僋愭摢丒搑拞偱偺憓擖丒嶍彍偑崅懍壔偝傟傞暘丄vector<array<char>> 偵斾傋偰僷僼僅乕儅儞僗偑岦忋偡傞偲婜懸偱偒傞丅
屌掕僒僀僘偵偡傞偺偼丄
庡婰壇偑懌傝側偔側傝奜晹婰壇憰抲偵僗儚僢僾傾僂僩偡傞応崌偺僗儚僢僾椞堟娗棟張棟偺娙棯壔傪恾傞偨傔丅
庡婰壇偺巊梡儊儌儕検傪愡栺偡傞偨傔偵丄僽儘僢僋僒僀僘偼屌掕偱偼側偔忋尷抣傪帩偮傛偆偵偵偡傞偺傕堦埬偱偁傞丅
奜晹婰壇偺堦帪揑偵曐懚偡傞応崌偼忢偵忋尷僒僀僘暘偺梕検偑偁傞偲傒側偣偽丄
僗儚僢僾椞堟娗棟偼屌掕僽儘僢僋僒僀僘偺張棟偱廩暘偲側傞丅
娗棟僋儔僗傪 vector 偐傜 gap_vector 偵曄偊偨傕偺丅
僽儘僢僋偺憓擖嶍彍偑嬊強揑偐偮昿斏偱偁傟偽丄僷僼僅乕儅儞僗偺岦忋偑婜懸偱偒傞丅
億儕僔乕傪梡偄偨僋儔僗傪掕媊偟丄嬶懱揑側僐儞僥僫僋儔僗偼僥儞僾儗乕僩僷儔儊乕僞偱梌偊傞丅
僽儘僢僋偺堏摦傪崅懍壔偡傞偨傔丄僽儘僢僋傊偺 boost::shared_ptr<block_t> 傪僐儞僥僫偵奿擺偡傞傛偆偵偟偨丅
template<typename CharType,
template<typename CharType, class Allocator = std::allocator<CharType>> class _Container,
int BLOCK_SIZE = DEF_BLOCK_SIZE>
struct Block
{
typedef _Container<CharType> Container;
typedef typename Container::iterator ContainerIterator;
size_t m_line_size; // 僽儘僢僋偵娷傑傟傞夵峴悢乮\r\n 偼傂偲偮偲悢偊傞乯
Container m_buffer;
.....
};
template<typename CharType,
// 僽儘僢僋傪娗棟偡傞僐儞僥僫僋儔僗
template<typename CharType, class Allocator = std::allocator<CharType>> class _BlockContainer,
// 僽儘僢僋撪偺暥帤傪娗棟偡傞僐儞僥僫僋儔僗
template<typename CharType, class Allocator = std::allocator<CharType>> class _DataContainer,
int BLOCK_SIZE = DEF_BLOCK_SIZE>
class edit_buffer_blocks
{
typedef Block<CharType, _DataContainer, BLOCK_SIZE> block_t;
typedef typename block_t::Container Container;
typedef typename Container::iterator ContainerIterator;
typedef std::gap_vector<boost::shared_ptr<block_t>> Blocks;
typedef typename Blocks::iterator BlocksIterator;
typedef typename Blocks::const_iterator BlocksConstIterator;
private:
Blocks m_blocks;
size_t m_char_size;
size_t m_line_size;
.....
};
僽儘僢僋梫慺悢傪32*1024偲偟偰僷僼僅乕儅儞僗傪寁應偟偨丅
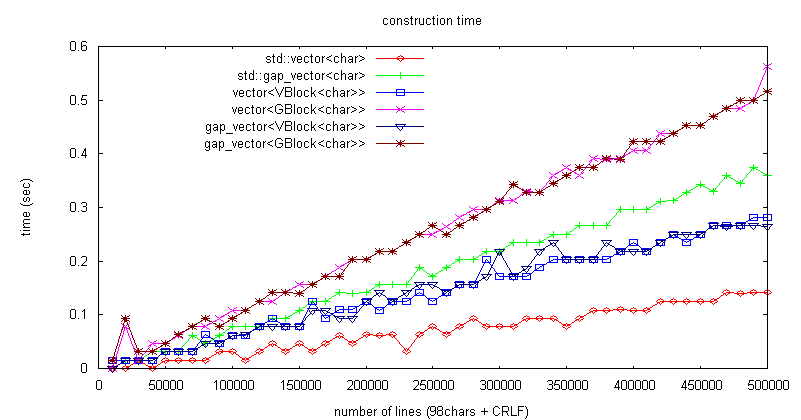
vector 偑 gap_vector 傛傝崅懍側偺偼丄僨乕僞僞僀僾偑婎杮宆偺応崌偺嵟揔壔偑棙偄偰偄傞偨傔丅
僽儘僢僋傪娗棟偡傞僐儞僥僫偺惈擻傛傝傕暥帤傪娗棟偡傞僐儞僥僫偺惈擻偑巟攝揑丅
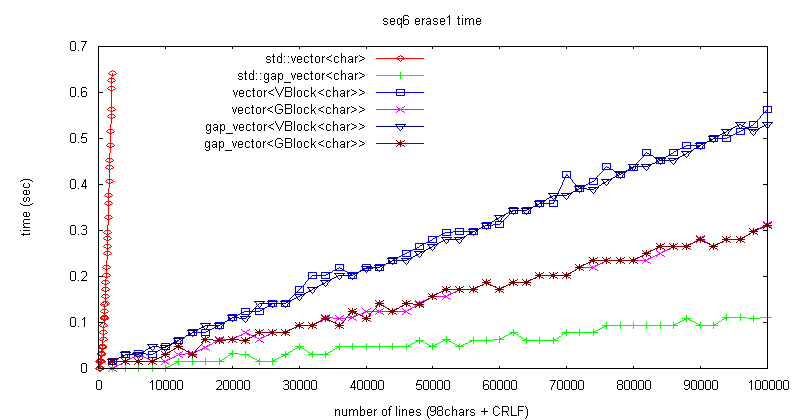
10枩峴 = 100*10枩 = 1000枩僶僀僩側偺偱丄10M/32K = 320僽儘僢僋丅
僽儘僢僋悢偑彮側偄偺偱娗棟僋儔僗偑 vector 偲 gap_vector 偱僷僼僅乕儅儞僗偺嵎偑偱側偄丅
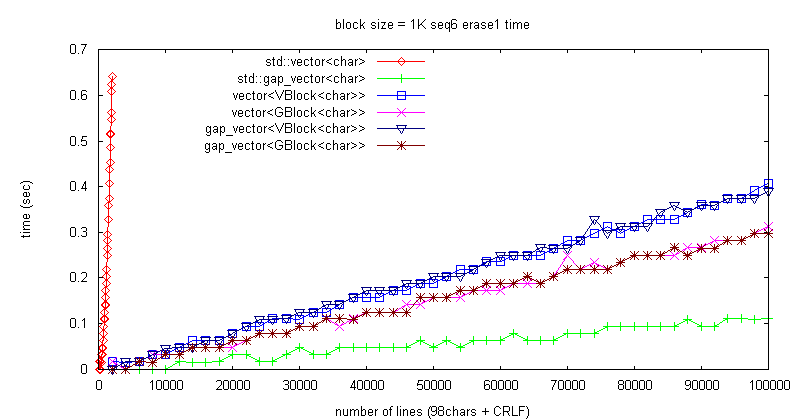
壓恾偼僽儘僢僋僒僀僘傪 32K 偐傜 1K 偵曄峏偟偰傒偨傕偺丅
gap_vector 偺応崌偼丄張棟懍搙偑傎偲傫偳僽儘僢僋僒僀僘偵埶懚偟側偄偑丄
vector 偺応崌偼僽儘僢僋僒僀僘偑彫偝偔側傟偽僨乕僞堏摦検偑尭傝崅懍偵側傞丅
僽儘僢僋僒僀僘丗256僶僀僩偱丄gap_vector 偲傎傏摨偠張棟帪娫偵側偭偨丅
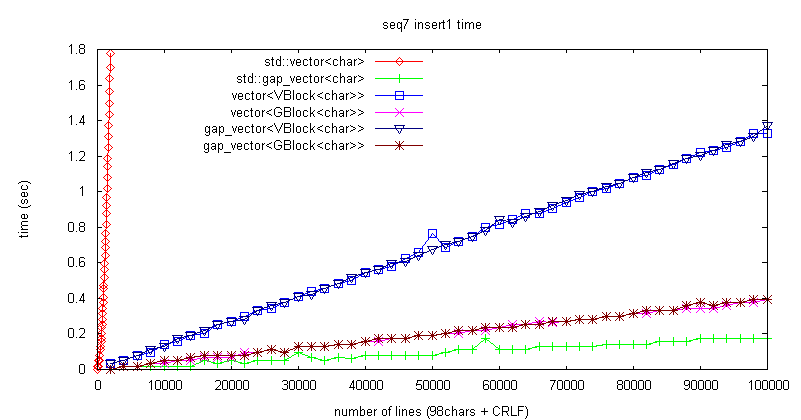
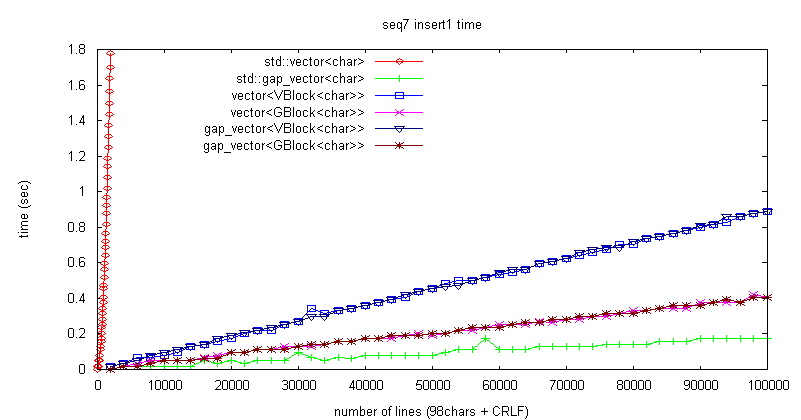
杮峞偺嶍彍張棟帪娫寁應偱偼僽儘僢僋屄悢偑憹尭偟側偄偨傔丄僽儘僢僋悢偑憹壛偡傞憓擖張棟偱帪娫寁應傪峴偭偰傒偨丅
偑丄僽儘僢僋憹壛偵敽偆
暥帤僐儞僥僫傪暿偺僐儞僥僫偱娗棟偡傞偙偲偱怴偨側僨乕僞峔憿傪峔抸偱偒傞丅
僽儘僢僋乮屌掕挿攝楍椶乯傪梡偄偨僨乕僞峔憿偼扨弮偱丄gap_vector 偵斾傋偰傕偦傟傎偳僷僼僅乕儅儞僗傪懝側傢偢偵 嫄戝僒僀僘僼傽僀儖偵傕懳墳壜擻偱偁傞丅
僔乕働儞僗僨乕僞傪奿擺偡傞偺偵嵟傕帺慠側僨乕僞峔憿偼攝楍椶偩偑丄 屌掕挿丒壜曄挿攝楍偵僥僉僗僩傪奿擺偟偨応崌丄枛旜埲奜偱偺曇廤憖嶌乮憓擖丒嶍彍乯偵僨乕僞偺堏摦張棟傪敽偆偨傔丄 O(N) 偺帪娫傪梫偡傞丅
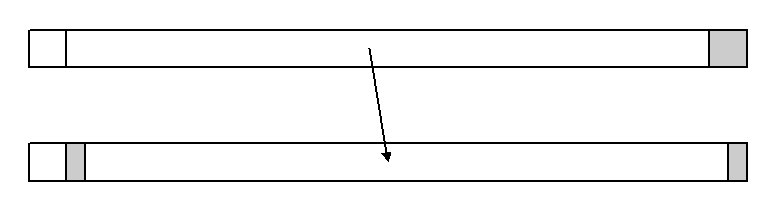
懍搙掅壓傪杊偖偵偼僨乕僞偺堏摦傪峴傢側偄傛偆偵偡傞偲傛偄丅
僗僷儞傪僐儞僥僫偱娗棟偡傞偙偲偱僔乕働儞僗僨乕僞傪昞尰偡傞丅
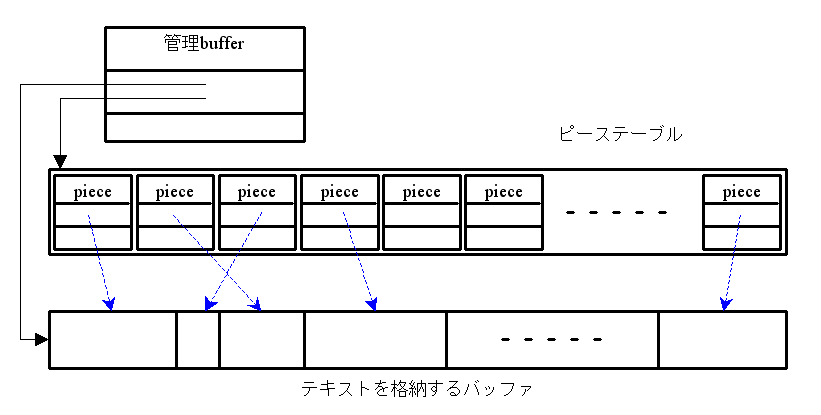
僗僷儞傪僺乕僗乮piece乯偲傛傃丄僺乕僗傪娗棟偡傞僐儞僥僫傪僺乕僗僥乕僽儖乮piece table乯偲屇傇丅
僺乕僗偺嬶懱揑側幚憰曽朄偲偟偰偼丄埲壓偺傛偆側傕偺偑峫偊傜傟傞丅
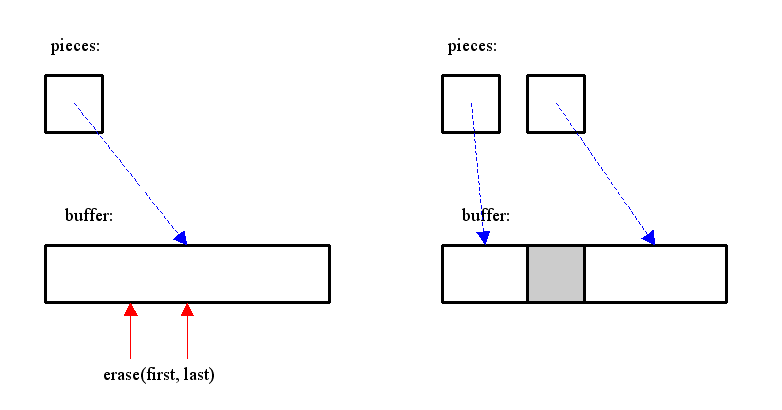
曇廤張棟丗
僺乕僗搑拞偺暥帤傪嶍彍偡傞応崌偼丄僺乕僗傪暘妱偡傞丅
[Delete] 傪楢懕偟偰墴偟偨応崌偺條偵丄捈慜偵嶍彍偟偨斖埻偺師偺暥帤傪嶍彍偡傞応崌偼丄 僺乕僗偑曐帩偡傞僗僷儞愭摢忣曬傪廋惓偡傞偩偗偱傛偄乮暥帤悢忣曬傪曐帩偟偰偄傞応崌偼僨僋儕儊儞僩傕昁梫乯丅
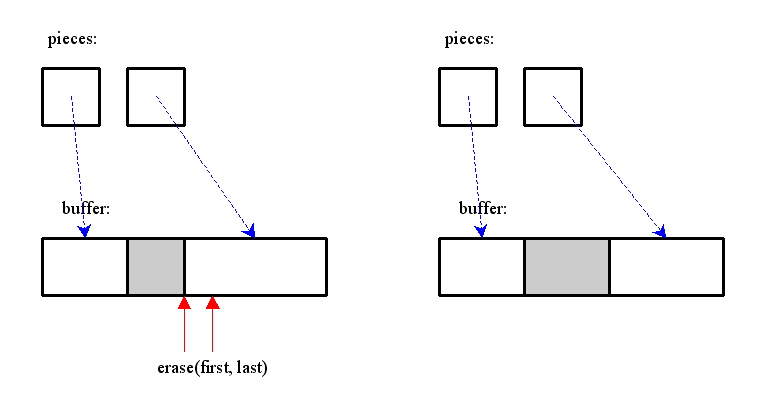
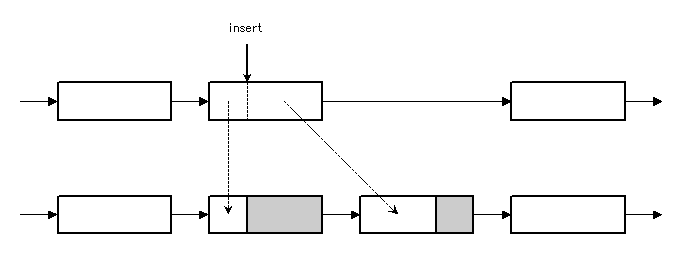
僺乕僗搑拞偵暥帤傪憓擖偡傞応崌偼丄僺乕僗傪暘妱偟丄娫偵怴婯僺乕僗傪憓擖偡傞丅
憓擖偝傟偨暥帤偼僶僢僼傽偵捛壛偝傟丄怴婯僺乕僗偼偦傟傪巜偡丅
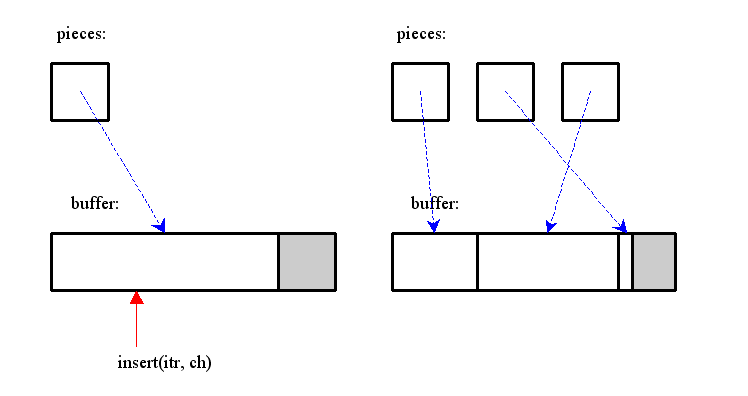
懕偗偰暥帤傪憓擖偡傞応崌丄憓擖偝傟偨暥帤偼僶僢僼傽偵捛壛偝傟丄捈慜偵憓擖偟偨僺乕僗傪廋惓偡傞 乮僺乕僗偵娷傑傟傞暥帤悢傪憹壛偝偣傞 or end 億僀儞僞傪峏怴偡傞乯
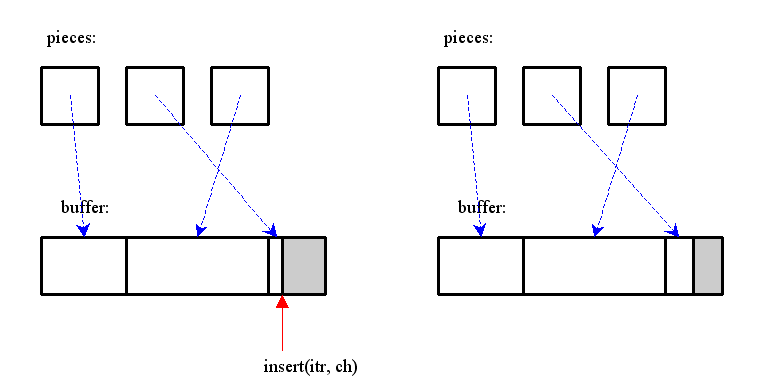
摿挜丒峫嶡丗
撪晹僶僢僼傽暥帤僐乕僪亖僀儞僞僼僃乕僗暥帤僐乕僪偲偟偰幚憰偟偨丅
僺乕僗偼俀偮偺億僀儞僞偱峔惉偡傞傛偆偵偟偨乮8byte乯丅
僺乕僗傪娗棟偡傞僐儞僥僫偼億儕僔乕偱巜掕壜擻偵偟偨丅
template<typename CharType,
// 僺乕僗傪娗棟偡傞僐儞僥僫
template<typename CharType, class Allocator = std::allocator<CharType>> class _PieceContainer>
class edit_buffer_pt
{
.....
};
piece_table<char> 偺僷僼僅乕儅儞僗寁應傪峴偄, gap_vector<shared_ptr<gap_vector<char>>>, gap_vector<char>
偲偺斾妑傪峴偆丅
應掕崁栚偼埲壓偺4崁栚偲偡傞丅乮僶僢僼傽峔抸帪儊儌儕巊梡検偵偼嵎偑柍偄偺偱徣棯偟偨乯
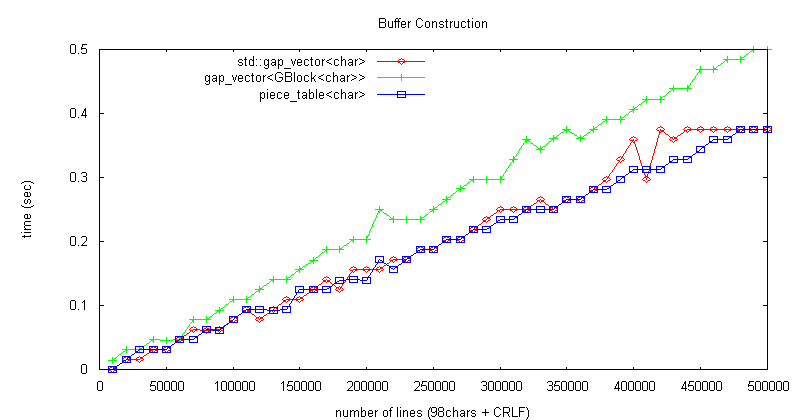
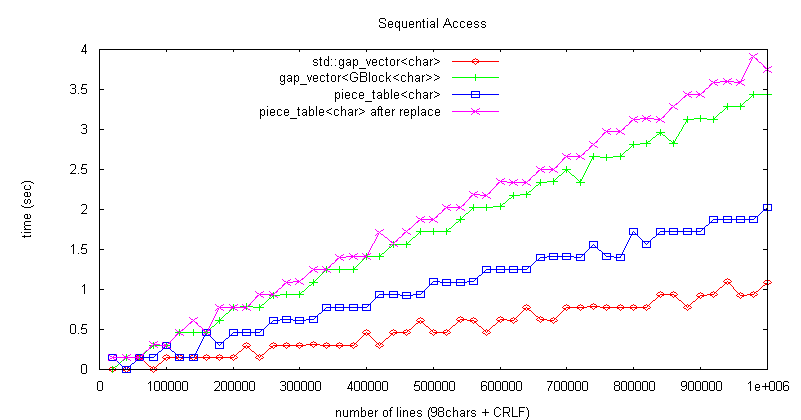
僔乕働儞僔儍儖傾僋僙僗張棟懍搙偼忋恾偺傛偆側應掕寢壥偲側偭偨丅
gap_vector<char> 偼曇廤傪峴偭偰傕丄1暥帤偁偨傝偺僔乕働儞僔儍儖傾僋僙僗懍搙偑曄壔偡傞偙偲偼側偄偑丄
piece table 偺応崌偼丄僺乕僗偵娷傑傟傞暥帤悢偑尭傝丄僺乕僗屄悢偑憹偊傞偺偱丄僀僥儗乕僞偺張棟偑廳偔側傞丅
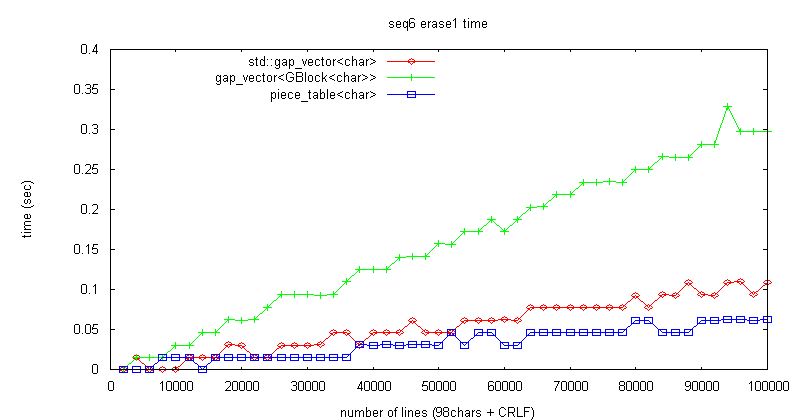
100僶僀僩仏10枩峴 = 1000枩暥帤側偺偱丄7暥帤偵1暥帤嶍彍偟偨応崌偺僺乕僗悢偼 1000枩/7 = 142枩僺乕僗偲側傞丅
尰嵼偺幚憰偱偼1僺乕僗偺儊儌儕徚旓検偼8僶僀僩側偺偱丄142枩*8 = 1142枩僶僀僩傕偺梕検傪徚旓偡傞偙偲偵側傞丅
偙傟偼尦偺僶僢僼傽梕検偺 8/7 偺僒僀僘偱偁傞丅
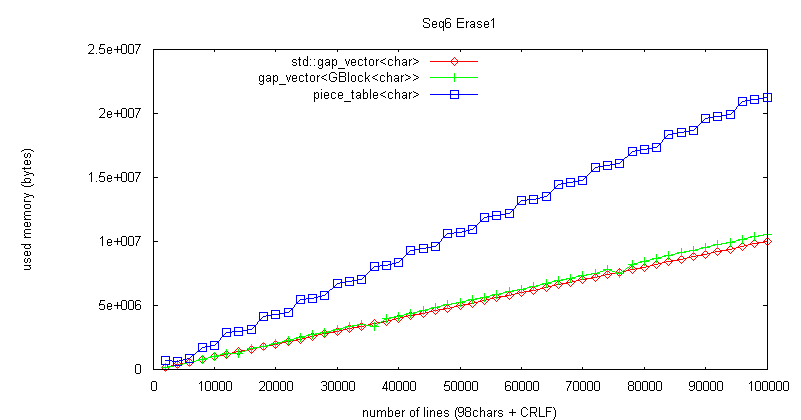
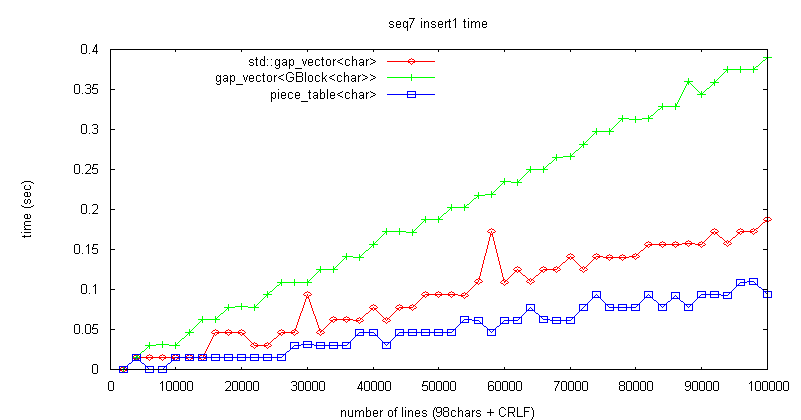
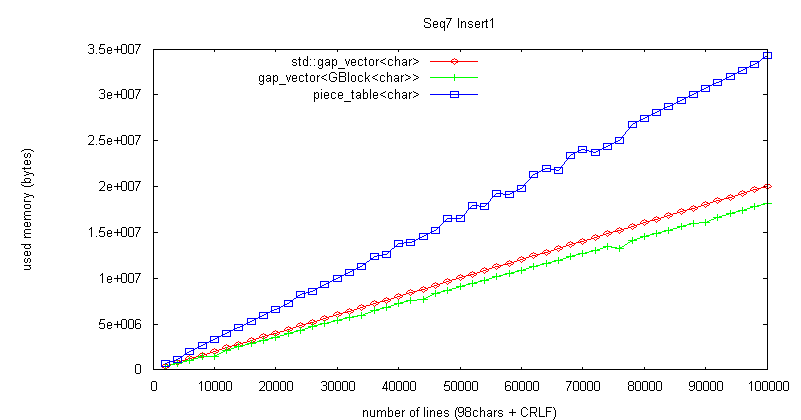
曇廤張棟偼丄gap_vector<char> 暲偵崅懍偱偁傞丅曇廤売強偑旕嬊強揑偱偁偭偰傕偍倠丅
彫僺乕僗偑戝検偵偱偒側偄尷傝丄儊儌儕岠棪偼傛偄丅
戝検偺彫僺乕僗偑儊儌儕傪徚旓偡傞栤戣偼丄undo 偺偨傔偺忣曬傪曐帩偡傞応崌偵傕摨條偱偁傝丄
抳柦揑側栤戣偱偼側偄偲峫偊傞丅
僺乕僗僥乕僽儖偼僥僉僗僩傪奿擺偡傞僶僢僼傽傪僗儚僢僾傾僂僩偡傞婡擻傪慻傒崬傓偙偲偱壖憐僶僢僼傽壔傕壜擻偩偲峫偊傞丅
ViVi 3.x 偺僶僢僼傽僨乕僞峔憿偲偟偰壗傪嵦梡偡傞偐傪寛傔傞偨傔偵丄僶僢僼傽僋儔僗偺僀儞僞僼僃乕僗傪寛傔丄 奺庬僨乕僞峔憿傪幚憰偟丄僷僼僅乕儅儞僗傪寁應偟偨傒偨丅
僥僉僗僩傪儊儌儕偵偡傋偰撉傒崬傔傞応崌偵偼 gap_vector<char> 偼僥僉僗僩僄僨傿僞梡僶僢僼傽偺僨乕僞峔憿偲偟偰
儊儌儕岠棪丒張棟懍搙丒幚憰梕堈惈偺揰偱丄傕偭偲傕桪傟偨僨乕僞峔憿偲尵偊傞丅
儊儌儕偵偡傋偰撉傒崬傔側偄傛偆側嫄戝僥僉僗僩偺応崌丄僺乕僗僥乕僽儖側偳偺奒憌揑僨乕僞峔憿傪嵦梡偡傞昁梫偑偁傞丅
ViVi 3.x 偱偼丄撪晹 Unicode 壔丒嫄戝僼傽僀儖懳墳傪 3.03/04 埲崀偲偟偨偺偱丄
偦傟傑偱偼 gap_vector<char> 傪嵦梡偡傞偮傕傝偱偁傞丅
僋儔僗僀儞僞僼僃乕僗傪昗弨壔偟偰偄傟偽丄僨乕僞峔憿傪曄峏偟偰傕丄偦傟傪棙梡偡傞懁偺僜乕僗廋惓偼傎偲傫偳柍偄偼偢偱偁傞丅
嶲峫暥專